In this section of the chapter the “stack” data structure is introduced. Stack data structures are used, among other things, to model the behavior of stacks of real-world objects. In order to understand this structure let’s begin by thinking about a simple stack of blocks, such as the one shown in . In this stack “A” is the top block, “B” is beneath “A”, and “C” is the bottom block. Assuming the blocks were added one at a time, how must this stack have been built? Well, first the bottom block, “C”, must have been set, then “B” would have been placed on top of “C”, and finally “A” would have been placed on top of “B”. Note that the blocks must be added to the stack from bottom to top: “C”, then “B”, then “A”. The last block placed on the stack will be the top block.
Now, let’s think about removing a block from the stack. As any child could demonstrate, the block that is most easily accessible is the top block, “A” in this case. Removing “A” from the stack leaves us with “B” sitting on top of “C”. It is interesting to note that the first item to be removed from the stack, “A”, was the last item added to the stack (remember the blocks were added in the order C-B-A). In fact, assuming you don’t “cheat” and grab an item from the middle of the stack, the last item added on the stack would always be the first taken off. For this reason, stacks are known as Last-In, First-Out (LIFO) structures.
As mentioned earlier, the stack data structure models the behavior of real-world stacks of objects. The two primary operations that can be applied to stack data structures are “push” and “pop”. The push operator is used to add a new item onto the top of the stack. The pop operator is used to remove the top item from the stack. Stack data structures do not support the removal of items from the middle of the stack. The stack of real-world blocks in could thus be modeled by applying the following operations to a initially empty stack data structure:
- Push C
- Push B
- Push A
The removal of “A” could be accomplished by issuing the Pop command.
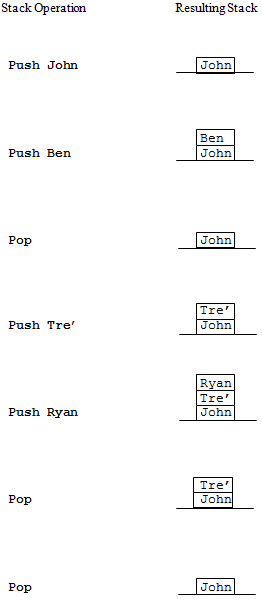
Operations on a stack
To be a little more formal, the stack data structure can be defined as a specialized type of list (an ordered sequence of items) in which all insertions to, and deletions from, the list take place at one end. The end of the list where the insertions and deletions are performed is known as the top of the stack. Stacks are usually drawn vertically, so that the item at “top” of the stack appears literally as the topmost item in the structure but they could just as easily be drawn “sideways” or “upside down”.
In order to ensure that you have a clear understanding of the behavior of the stack data structure, presents a sequence of stack operations and a pictorial representation of the stack that would result after each operation is applied. Note again that the “pop” operation always removes the last item placed on the top of the stack.
Now that you have some understanding of how stacks behave, it is natural to ask “so what?” Why are stacks of interest to computer scientists?
In the real-world we routinely encounter stacks of objects – CD’s, dishes, bills. We use these stacks to temporarily hold objects until we are ready to use or “process” them in some way. One important characteristic of all stacks – both the real-world type and their software counterpart – is that due to their LIFO nature they reverse the order of the objects they hold. (If you place three CD’s in a stack, Cracker, then Pink Floyd, then Everclear, and then play the top one, you will be listening to Everclear, not Cracker.) In everyday life, we tend to use stacks in situations where order is unimportant, such as for holding identical, non-perishable items like dinner plates.
In a similar manner, stack data structures are used by computer software to temporarily hold data “objects” until they can be processed by the computer. However, instead of de-emphasizing the LIFO nature of stacks, in computing stacks tend to be used almost exclusively in situations where we specifically want to process items in the opposite order than they were added to the structure.
One common use of stacks in computing is to manage the execution of interruptible tasks. The utility of stacks for this purpose can easily be seen by a real-world analogy. Say you are typing an English paper (Task One) and the phone rings. You pick up the phone (i.e., place Task One on the stack of “on hold” processes) and begin a conversation with your significant other, Pat (Task Two). During this conversation your phone clicks indicating someone else it trying to call you, so you put Pat on hold (i.e., place Task Two on the stack of “on hold” processes) and take a call from your mom (Task Three). After a brief talk with mom, you switch back to Pat (i.e., after Task Three completes, you pop Task Two off the stack of “on hold” processes and restart it from the point you left off). Finally, after a not-so-brief conversation with Pat, you return to your English paper (i.e., after Task Two completes, you pop Task One off the stack of “on hold” processes and restart it where you left off).
Note that in order to handle these interruptible tasks properly, a data structure such as a stack that incorporates Last-In, First-Out behavior must be employed.
A real-world example of a queue (or waiting line)